




There are several strategies used by professionals to build high-ranking websites. Many of them rely on having good Uniform-Resource-Locator (URL) structure; making it easy for web-crawlers to transverse through the website easily.
Do you want Google to return a URL of your website on the first page when a certain keyword is searched? Well, the Google team - who else? - has compiled a list of advice on how to design(structure) your links to build a successful web presence; ultimately getting to the first page. This talk was given at this year’s (2018) Google I/O in San Francisco by Maria Moeva and John Muller. Both of Google.
Use Meaningful URLs
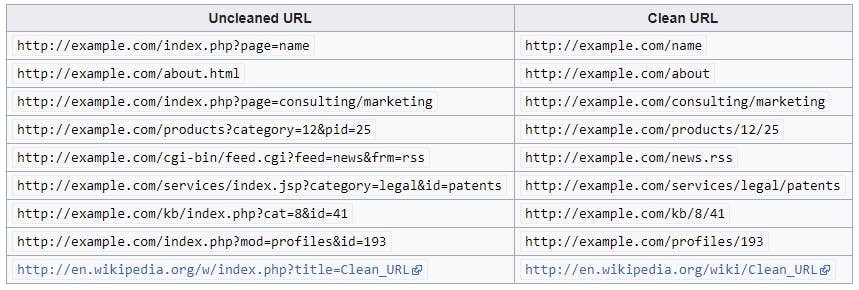
Credit : Clean URL, June 2018
Working with explanatory URLs makes it easy for the internet-audience (both humans and bots) to navigate a site. By removing characters - like ‘?’ and ‘#’ - from urls, less processing is required both cognitively from humans and textually from computers. It makes it easier to know what section of the website you are, and how to get to other pages without knocking on the ' 404 error ’ door. As seen in the image below, it also means the browser is not tricked into supplying another page when user are requesting for something different.

According to IBM, the best way to build a clear URL is to structure in-context; mapping related web-pages together and linking them in groups together.
Use Consistent URLS For The Same Page For many websites on the internet, the home-page has differing doors. One could get ‘example.com’ and ‘example.com/index’ rendering the same view. This action alone confuses the bot that is crawling that website, because it does not know which instance to serve agents requesting for that web-page. Also, there will more URL sent to the crawler for processing.
By removing ambiguity, one is able to help the crawler make its decision efficiently; which is good for our ranking.
 Don't skip the critical metadata
Don't skip the critical metadata
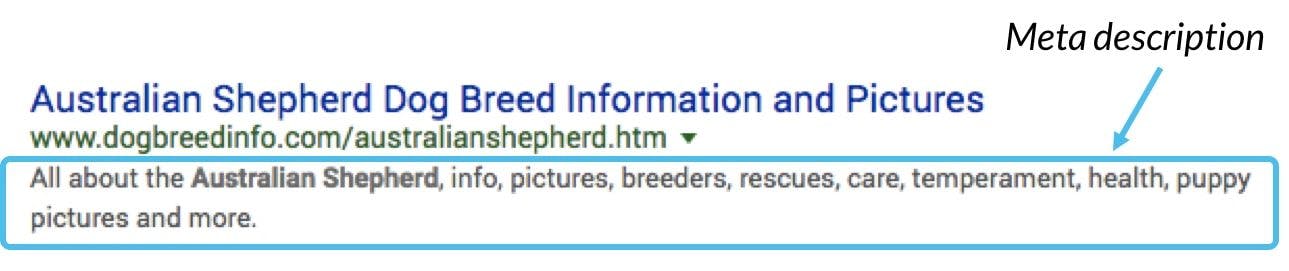
Credit : Example showing content of a web-page.
The era of web 2.0 is fizzling out; having lots of content that are not descriptively mapped to a certain model does not help computers on the internet. Web 3.0 promises to allow programs know what content is on your page and how serve the audience requesting for them. But they need you to do your part. Meta-Data is the way we tell the browser what contents we have on our website. It is also the way Search Engine categorise your website. Each browser - Safari, Chrome, Mozilla - has its own peculiarity and demand a certain way to structure these meta-data.
Covering the basic content-description is the best way to serve all modern web clients at once. These basic descriptions are also critical to the classification given to that web-page. Examples of these critical-meta-data are; doctype, character-set, viewport, canonical-links, page title, and description. Doctypes informs the browser of the type of file to expect so as to format it accordingly; for modern day webpages it should be “html.”
Note that bombarding a web-page with too many ‘word-tags’ confuses the classifying program. If your website is exclusively about hotels, do not include real estate or residential property. That means the your website will no longer be in a niche category. This principle also applies to duplicate meta-descriptions.
Integrate semantic-web structure Web 3.0 is here to stay. All browsers implement features differently but they have protocols they conform to. Each crawler expects your website to be consistent with these protocols.
For example When linking between pages or websites, use the anchor element! Don't use non-semantic elements if you don't have to, and if you do, make it an addition rather than an alternative. A simple reason being all browsers understand the anchor tags. Using standard, non-deprecated HTML-5 tags allows all clients to receive consistent code and process them accordingly.
Some of the images above were curated by Ire Aderinokun.